ALINEA - Aide
(c) 2000-2006 - Olivier Kraif
Sommaire
3.1.1 Segmentation des phrases (format TXT)
3.1.3 Exemple de format CESAna
3.1.4 Exemple de format CESAlign
4.1 Généralités sur l'alignement
4.2.1 Phase I : Extraction de points d'ancrage
4.2.2 Phase II : Calcul du meilleur chemin d'alignement
4.2.3 Phase III : Extraction des correspondances lexicales
5.1. Menu Aligner / Aligner directement
5.2. Menu Aligner / Aligner en série
5.3. Menu Aligner / Nouveau Projet
5.5 Menu Aligner / Cloture transitive
6. Fenêtre Navigateur bi-textuel
6.3.1 Représentation des tokens
6.4 Enregistrement / Exportation
Alinea est un programme dédié à la constitution et à l'édition de corpus bilingues alignés (textes en relation de traduction mutuelle).
Alinea permet d'aligner des textes, de comparer deux alignements, d'éditer un alignement existant, d'enregistrer cet alignement sous des formats divers.
Alinea est distribué gratuitement. Ce n'est pas un logiciel commercial suivi de prêt par une équipe de programmeurs, susceptible d'évoluer rapidement à la demande des utilisateurs. Son auteur se dégage donc de toute responsabilité quant à l'uilisation qui en est faite, et ne prend aucun engagement quant au suivi de développements futurs.
Néanmoins, si vous constatez des bogues ou des dysfonctionnements, ou si vous avez des suggestions à apporter, merci d'envoyer vos remarques à Olivier.Kraif@u-grenoble3.fr, avec le texte [ALINEA] figurant dans le titre de votre message.
La présente version ne fonctionne que sous Windows (2000, NT, XP ou supérieur). Il est recommander d'exécuter alinea sur un Pentium 3 (au minimum) équipé de 256 Mo de RAM.
Dézipper la totalité de l'achive Alinea.zip dans un dossier de votre choix. Pour lancer le programme, il suffit d'éxecuter Alinea.exe. Aucune modification du registre n'est faite. Pour désinstaller Alinéa, il suffit de supprimer le dossier ainsi décompressé.
Attention : si vous voulez lancer Alinea depuis votre bureau, il faut créer un raccourci (et non faire un copie de Alinea.exe, qui doit rester dans son dossier d'origine).
Les fichiers nécessaires au fonctionnement d'Alinea sont :
- le fichier de choix par défaut : default.dat (contient des informations sur les options par défaut de la dernière session). Si ce fichier est corrompu, il suffit de le supprimer pour le regéner.
- les fichiers de paramètres : param.l1.l2.dat. Ces fichiers contiennent les jeux de paramètres susceptibles de changer avec les couples de langue (p. ex. l1=en, l2=fr pour le couple anglais-français). Par une simple copie/renommage de param.l1.l2.dat, vous pouvez vous créer un fichier adapté pour un couple de votre choix.
|
ID
|
Codage
|
Type de format
|
| txt | ISO-Latin-1 / UTF-8 |
Texte brut. Alinea réalise la segmentation en phrases à
partir d'une grammaire régulière basée sur la ponctuation.
|
| txs | ISO-Latin-1 / UTF-8 |
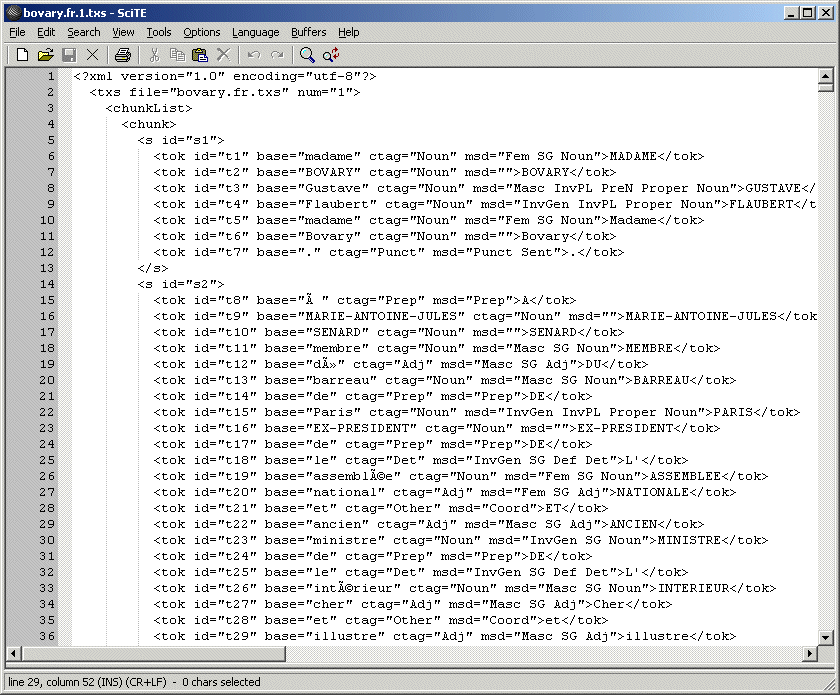
Texte étiqueté simplifié |
| ces | ISO-Latin-1 / UTF-8 |
Texte étiqueté - Norme CESAna (http://www.cs.vassar.edu/CES). Comporte obligatoirement une segmentation en phrases, et optionnellement une segmentation en token (avec des tags). |
| xip | ISO-Latin-1 / UTF-8 | Texte étiqueté avec dépendances (sortie ntmparse du parseur XIP de Xerox) |
| cesalign | ASCII | Fichier d'alignement |
La segmentation des phrases est une opération cruciale pour l'alignement : si les deux textes à aligner possèdent des segmentations parallèles, les résultats de l'alignement n'en seront que meilleurs.
Les règles de segmentation en phrase pour une langue l1 sont rengistrées dans le fichier segmentation.l1.txt du dossier Param. Si ce fichier n'existe pas, c'est segmentation.default.txt qui sera pris en compte.
Voici les règles appliquées pour le français.
Les marques de fin de phrases sont : le point, le point virgule, les deux points, le point d'exclamation, le point d'interrogation, la marque de paragraphe (Ascii 10-13). Le point peut néanmoins intervenir dans la reconnaissance des tokens (tous les points ne sont donc pas des fins de phrases).
Espacement= tabulation | espace
Token = SuiteAlphaNum | DateNum | Abrev | AcroMin | AcroMaj | AutreCar
AlphaNum = [A-Za-z0-9]+
p.ex. "Bonjour" "A4"
DateNum = ([0-9]+( . | , | - | / ))+[0-9]*
p.ex. "12/07/2004"
"132-3" "3000,23"
Abrev = M. | MM. | etc. | cf. | Cf. | p. | pp. | ex. | al. | MR. | MRS. | eg.
AcroMin= [a-z]+(.[a-z]+)+(.|epsilon)
p.ex. s.n.c.f. so.na.co
AcroMAJ= [A-Z]+(.[A-Z]+)+(.|epsilon)
p.ex. S.N.C.F. UN.SI.
AutreCar = , % ^$"'(-_)=&~#{[|`\^@]}¤/§¨£ etc...
FinDePhrase= . | ; | : | ? | ! | \n
Phrase = (Token Espacement+ )* FinDePhrase
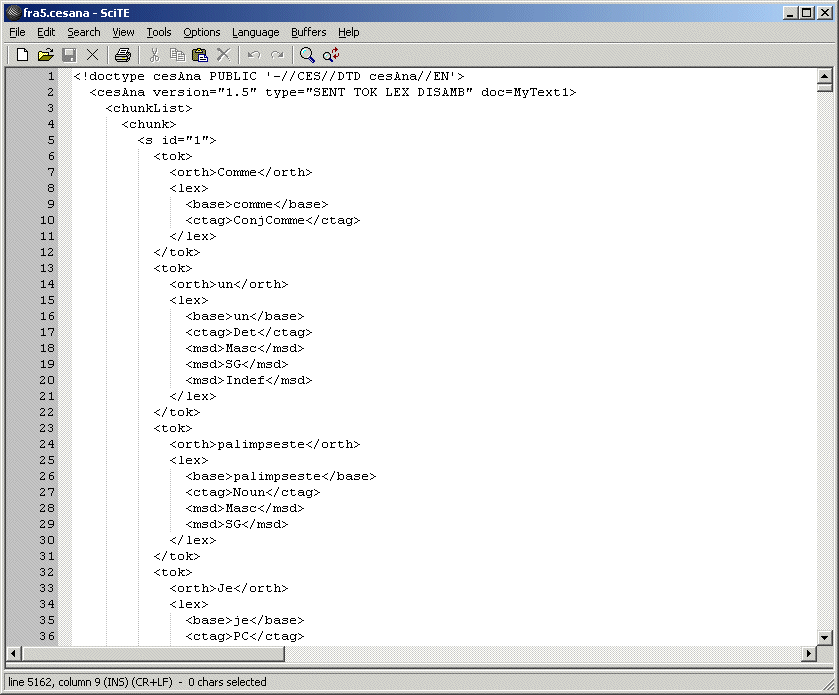
Cesana sans tokenisation
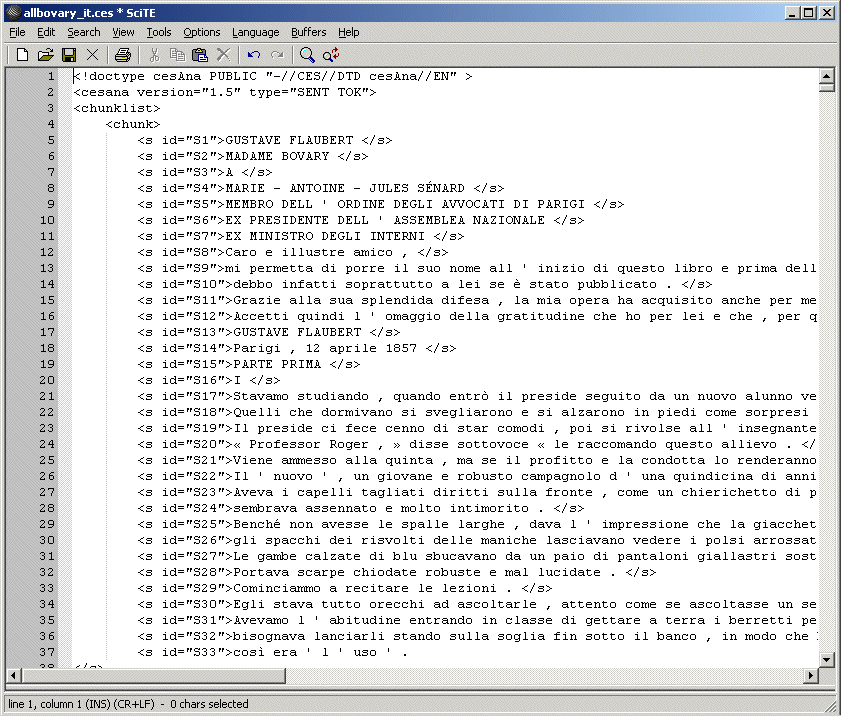
Un fichier d'alignement est codé séparément des deux textes source et cible. Un tel fichier enregistre une suite de correspondances établies entre des segments des deux textes. Ces segments peuvent concerner des phrases ou des lexèmes. Dans l'exemple ci-dessous, on a des correspondances entre phrases. Les groupes de phrases en correspondance sont séparés par des point virgule à l'intérieur des attributs xtargets. Alinea est capable d'extraire un alignement bilingue à partir d'un fichier contenant l'alignement de plus de deux langues : il faut seulement lui indiquer les positions respectives correspondant aux deux langues sélectionnées.
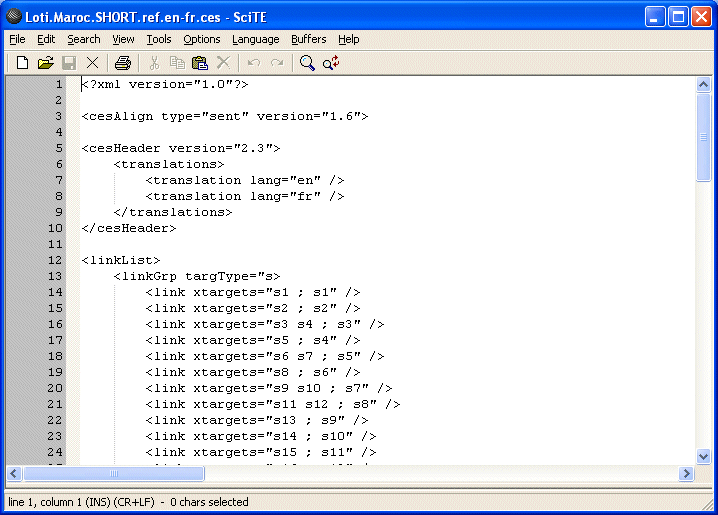
Le format de base pour enregistrer un alignement est le format CESAlign. Néanmoins, Alinea peut exporter les fichiers d'alignement en texte brut et en html, afin de permettre une lecture directe de l'alignement résultat.
Lorsqu'on coche l'option de filtrage, et que l'on définit des expressions de recherche, il est possible d'exporter le résultat sous un format de type concordance, les expressions trouvées se retrouvant alignées verticalement : il s'agit du format KWIC (Key Word In Context), qui est enregistré en texte brut.
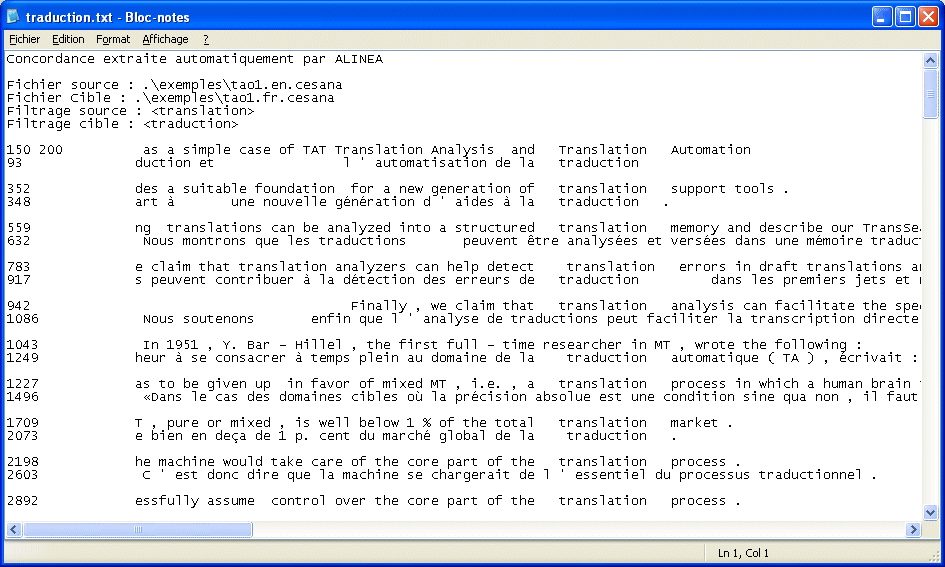
Exemple de sortie au format HTML :

Les techniques d'alignement s'appliquent à des textes parallèles (en général un texte et sa traduction, mais aussi, dans certains cas, deux traductions du même texte). Elles visent à rendre explicite la relation d'équivalence traductionnelle, et peuvent s'appliquer à différents niveau de granularité : sections, paragraphes, phrases, syntagmes, lexèmes, etc... Les systèmes d'alignement automatique obtiennent en général des résultats satisfaisant au niveau des phrases.
On constate dans la pratique que la traduction ne conserve pas toujours le découpage en phrases du texte source, comme dans l'exemple suivant :
[86] C ' était le curé de son village qui lui avait commencé le latin , ses parents , par économie , ne l ' ayant envoyé au collège que le plus tard possible .
[88] It was the cure of his village who had taught him his first Latin ;
[89] his parents , from motives of economy , having sent him to school as late as possible .
(N.B.: tout dépend bien entendu de ce qu'on entend par phrase, étalon qu'il est très difficile de définir formellement sur un plan linguistique ou typographique).
Il faut donc être à même d'effectuer des regroupements pour mettre les segments en correspondance : c'est l'objet des algorithmes d'alignement. On peut représenter un alignement par un ensemble de points dans un espace à deux dimensions, avec les numéros des segments sources en abscisse et les numéros des segments cibles en ordonnée. Cette configuration, qui en général est voisine de la diagonale du bi-texte, est appelée chemin d'alignement. Le chemin peut également être représenté comme une suite de regroupement ou transitions : 1:1, 1:0, 0:1, 1:2, etc.
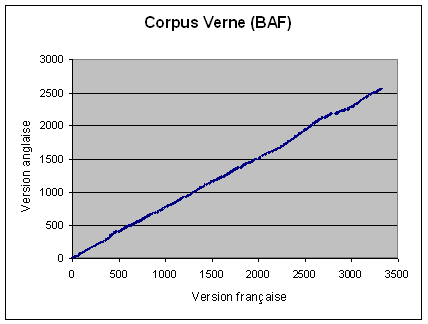
Alinea permet d'enchaîner trois phrases d'alignement :
Les textes parallèles contiennent fréquemment des équivalents traductionnels identiques, nommés transfuges : il s'agit en général de nombres, de noms propres, de sigles, d'emprunts, de mots apparentés.... Ces transfuges, souvent nombreux, comme dans l'exemple ci-dessous (en rouge), permettent d'extraire des points d'ancrage de qualité :
The Preparatory Committee for the Fiftieth Anniversary of the United Nations , established by the General Assembly in decision 46/472 of 13 April 1992 , held five meetings. Agreement was reached by consensus on a theme for the anniversary
Le Comité préparatoire du cinquantième anniversaire de l ' Organisation des Nations Unies , que l ' Assemblée générale a créé par sa décision 46/472 du 13 avril 1992 , s ' est réuni cinq fois et s ' est mis d ' accord sur le choix d ' un thème
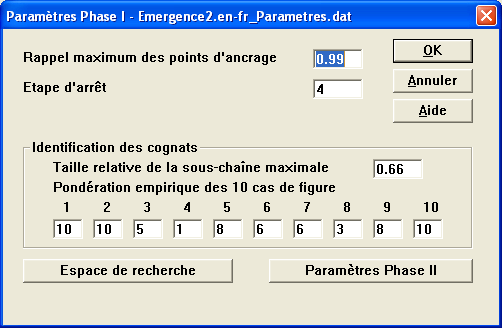
Etapes 1-4 : Alinea utilise ces transfuges lors des étapes 1-4 de l'extraction des points d'ancrage. A chacune de ces étapes, on considère une catégorie spécifique de transfuges :
On utilise d'abord les catégories de transfuges jugées plus fiables. Le processus d'extraction des points d'ancrage est itératif, et se répète à chaque étape jusqu'à stabilité. Pour chaque transfuge, on vérifie si les occurrences dans le texte source et dans le texte cible peuvent être appariées deux à deux (i.e. avec le même nombre d'occurrences). Si c'est le cas, ces appariements forment des points que l'on valide s'ils vérifient un certain nombre de critères :
Les points ainsi obtenus permettent de définir des zones préalignées : on peut alors répéter le même processus à l'intérieur de ces zones plus petites, où certains transfuges sont susceptibles d'être appariables, alors qu'il ne l'étaient pas à l'étape précédente (car il n'avaient pas le même nombre d'occurrences dans la source et dans la cible).
Etape 5 : Extraction de points d'ancrage basée sur les mots apparentés (cognats)
Pour des langues apparentées, comme l'anglais et le français, on observe de très nombreux équivalents traductionnels sous la forme de mots apparentés, ou cognats. Ces mots, qui présentent souvent une ressemblance formelle importante (comme les unités en bleu dans l'exemple précédent), peuvent être identifiés automatiquement : pour Alinea, toute paire de mots constitue un couple de candidats cognats si on peut en extraire une sous-chaine commune d'une longueur au moins égale à 66% de la longueur du mot le plus long (cette valeur de 66% peut être redéfinie dans les paramétrages).
Par exemple entre preparatory et préparatoire, on trouve la plus longue sous-chaîne commune : p-r-p-a-r-a-t-o-r
donc 9 caractères représentant 9/12=75% de préparatoire. Ce couple sera donc retenu comme paire de cognats potentiels.
Dans l'étape 5 de l'extraction des points d'ancrage, Alinea calcule des matrices de densité de cognats pour tous les couples de phrases appariables entre deux points d'ancrage déjà validés (étape 4). De ces matrices, de nouveaux points sont extraits pour les couples de densité maximale. Attention : cette étape est coûteuse en calcul, et elle est généralement annulée (cf. le chapitre Paramétrages).
La fonction d'un algorithme d'alignement est de déterminer quelle est la suite de transitions (1:1, 1:0, 0:1, 2:1, etc.) la plus probable. La probabilité d'une suite de transitions est généralement évaluée à partir des ressemblances observées entre les éléments appariés. Ces ressemblances sont mesurées à partir de différents indices : longueurs des phrases, lexique équivalent, densité de cognats, contenu sémantique voisin, etc. Sur la base de ces indices, on élabore une mesure inverse permettant d'évaluer la distance entre deux groupes de phrases. Le problème se résume alors à une question d'optimisation : comment déterminer le chemin le plus court (i.e. qui minimise la distance).
Le nombre de chemins possibles à travers l’espace bidimensionnel décrit par les deux textes est une fonction exponentielle de la taille des textes : pour trouver le meilleur chemin (i.e. celui qui obtient le meilleur score, la plus petite distance), il est donc exclu de tester tous les chemins possibles. L’algorithme de Viterbi, dit de programmation dynamique (R. Bellmann, 1957), apporte une solution élégante à ce problème d’optimisation : plutôt que de tester tous les chemins possibles, il est plus intéressant de ne calculer, pour chaque point de l’espace, que le meilleur sous-chemin qui relie ce point à l’origine. Or le meilleur sous-chemin parvenant à un point est fonction des meilleurs sous-chemins qui arrivent aux points situés juste avant : il peut donc être calculé de proche en proche, de façon récursive. Le chemin optimal – l’alignement final – ne sera autre que le meilleur sous-chemin reliant l’origine à la fin de l’espace. Pour des textes de taille moyenne n il y a n^2 sous-chemins à calculer, et la complexité globale de l’algorithme devient donc polynomiale. La réduction de l'espace de recherche autour de la diagonale permet d'assimiler le coût des calculs à une complexité linéaire.
Algorithme récursif
Cette technique est employée dans toutes les méthodes basées sur la recherche de la meilleure suite de transitions, comme celles de Gale & Church (1993) ou de Brown et al. (1991). Concrètement, pour un point de coordonnées (i,j), la distance du meilleur chemin menant à (i,j) est calculée en fonction des sous-chemins immédiats (i. e. qui rejoignent (i,j) moyennant une transition supplémentaire).
Dans le cas suivant, si l’on ne tient compte que des transitions (1:1), (1:0), (0:1), (2:1), (1:2), (2:2), on a :
FONCTION distanceMin(i,j) {
SI (i,j) n'appartient pas à l'espace de recherche ALORS RETURN +∞
SI D(i,j) est non vide ALORS RETURN D(i,j)
SINON {D(1:1) <- distanceMin(i-1,j-1) + d(P i-1;P’ j-1)
D(0:1) <- distanceMin(i,j-1) + d( ; P’ j-1)
D(1:0) <- distanceMin(i-1,j) + d(P i-1; )
D(2:1) <- distanceMin(i-2,j-1) + d(P i-2P i-1;P’ j-1)
D(1:2) <- distanceMin(i-1,j-2) + d(P i-1;P’ j-2P’ j-1)
D(2:2) <- distanceMin(i-2,j-2) + d(P i-2P i-1;P’ j-2P’ j-1)
D(i,j) <- min (D(1:1), D(0:1), D(1:0), D(2:1), D(1:2), D(2:2))
T(i,j) <- Argmin T D(T)
RETURN D(i,j)}
}
Où D (i,j) est la distance du sous-chemin optimal menant à (i,j)
d(P 1P 2..P n;P’ 1P’ 2..P’ m) est l’incrément de distance liée au couple (P 1P 2..P n;P’ 1P’ 2..P’ m).
T(i,j) est le numéro de la transition choisie pour prolonger le sous-chemin optimal.
L'alignement final est obtenu en calculant distanceMin(m,n) (où m et n sont les longueurs respectives des textes, en nombre de phrases), et en chaînant toutes les transitions de T(m,n) jusqu'au début des textes.
L’algorithme peut être appliqué à l’identique sur une plus grande étendue de transitions, du type (1:3), (3:2), (2:3), (3:2), etc. ce qui élargit la couverture des cas possibles, mais augmente aussi les branchements récursifs.
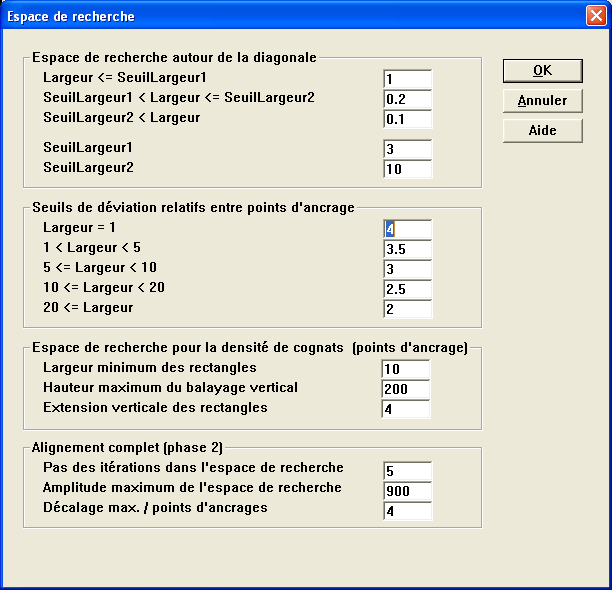
Espace de recherche
Pour la mise en oeuvre d'un tel algorithme, il suffit de disposer de deux tableaux de réels de dimension n*m, qui permettent de stocker les distances des sous-chemins D(i,j) à mesure qu'elles sont calculées, et les transitions correspondantes T(i,j).
Mais pour des raisons d'efficacité, on limite en général l'espace de recherche à une bande autour de la diagonale. Si on dispose de points d'ancrage issus de l'étape précédente, l'espace de recherche pourra encore être réduit, à l'intérieur des îlots de confiance ainsi dégagés. Entre deux points d’ancrage, on considère alors la sous-diagonale formée par la ligne idéale passant par ces deux points : l’espace de recherche peut être défini comme un intervalle centré sur cette ligne, un "couloir" dont la largeur est proportionnelle à la distance séparant les points d’ancrage. Si P 1 = (X 1,Y 1) et P 2 = (X 2,Y 2) sont les coordonnées de deux points d’ancrages successifs, l’espace de calcul est défini par la formule :
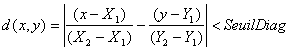
Mesure de distance
Une mesure classique de la distance correspondant à un groupe de phrases est celle proposée par Gale & Church (1993).
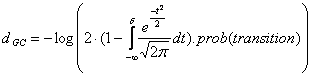
avec
![]()
l' = longueur du groupe de phrases cibles
l = longueur du groupe de phrases sources
c = moyenne du rapport des longueurs entre texte cible et texte source
s2= variance de ce rapport (cf. paramétrages de la phase II)
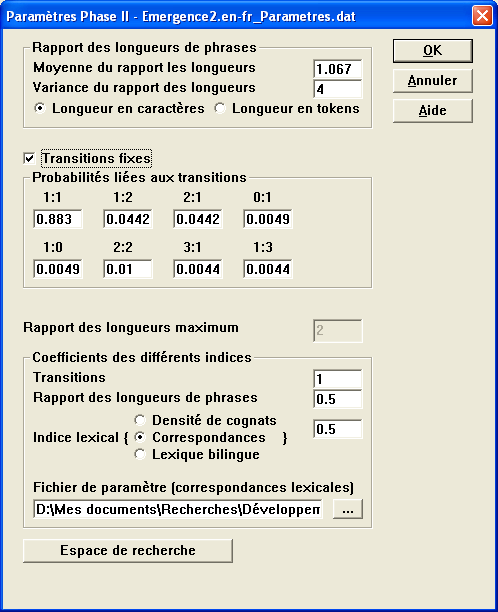
prob(transition) est la probabilité empirique du cas de figure considéré : (1:1) (1:0) (0:1) (1:2) etc.
Les valeurs proposées par Gale et Church sont les suivantes :
p(1:1) |
p(0:1) |
p(1:0) |
p(2:1) |
p(1:2) |
p(2:2) |
0,89 |
0,0425 |
0,0425 |
0,00495 |
0,00495 |
0,011 |
Alinea permet de travailler sur un ensemble de transitions étendues, selon deux cas de figure :
Tous ces paramétres sont accessibles et modifiables (cf. paramétrages de la phase II).
Cette distance n'intègre que deux indices : les longueurs de phrases (exprimées en nombre de caractères. ou en nombre de tokens) et les probabilités empiriques des transitions (le cas (1:1) étant le plus probable).
Alinea permet d'intégrer dans la mesure de distance d'autres indices au choix :
Les meilleurs résultats sont généralement obtenus en combinant ces sources d'information dans des proportions qui varient selon les couples de langues.
Pour déterminer si deux unités u et u' apparaissant dans un couple de phrases alignées sont en correspondance (i.e. sont des équivalents traductionnels), la principale source d'information vient de la comparaison des distributions de ces unités : on examine la fréquence de u dans le texte source, celle de u' dans le texte cible, et le nombre de fois où u et u' sont cooccurrentes (c'est-à-dire apparaissent dans des couples de phrases alignées). A partir de ces quantités, il est possible de construire différentes mesures d'association, sur des bases statistiques, permettant d'évaluer le degré d'association entre u et u'. Alinea se base sur la probabilité de l'hypothèse nulle (P0), c'est-à-dire la probabilité d'obtenir n12 cooccurrences par le simple jeu du hasard. Prenons l'exemple suivant (tiré de Jules Verne, Voyage au centre de la terre):
Que signifiait un pareil changement ?
What could be the meaning of such a change ?
Si on examine les occurrences et cooccurrences de signifier avec meaning et change dans un corpus de 27 000 couples de phrases, on a :
verbe-signifier : 32 occurrences
nom-change : 164
-> 1 cooccurrence
verbe-signifier : 32 occurrences
nom-meaning : 17 occurrences
-> 5 cooccurrences
Si l'on fait l'hypothèse nulle, l'observation d'une seule cooccurrence de signifier avec change est tout à fait probable (car ces cooccurrences sont en effet fortuites). En revanche, l'observation des 5 cooccurrences de signifier avec meaning est hautement improbable (car très supérieure à ce que le hasard aurait en effet produit) : cette très faible probabilité nous indique qu'il y a une association non fortuite entre ces unités : il s'agit en l'occurrence d'une relation d'équivalence traductionnelle.
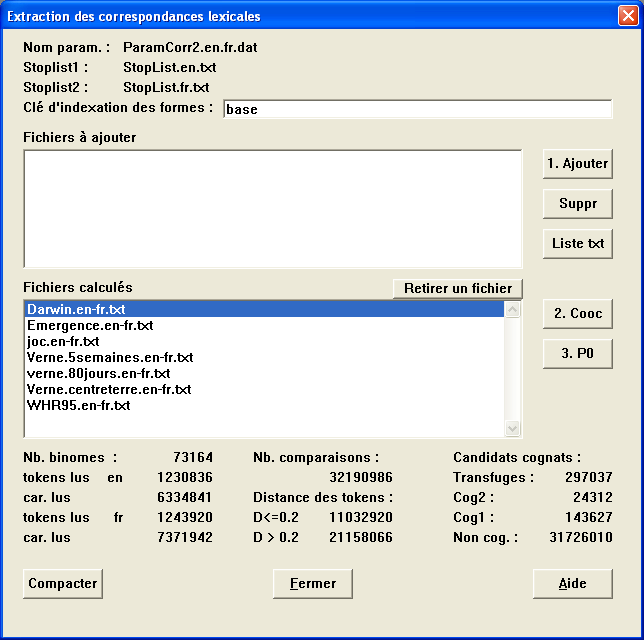
Pour extraire les correspondances lexicales, Alinea a donc besoin d'extraire, à partir d'un vaste corpus de textes alignés, des statistiques d'occurrences et de coccurrences, afin d'être en mesure de calculer P0. Nous estimons qu'il faut environ 1 million de mots dans chaque langue pour que ces statistiques assurent une couverture suffisante du lexique commun. Pour calculer ces statistiques, il faut utiliser les options Correspondances lexicales du menu Jeux de paramètres. Les fichiers de paramètres ainsi créés sont souvent volumineux (compter 250 Mo pour de bons résultats).
Afin d'améliorer l'extraction des correpondances, Alinea utilise des indices complémentaires, toujours en se basant sur la probabilité de l'hypothèse nulle : les positions dans les phrases alignées et les ressemblances formelles (candidats cognats). Ces techniques sont détaillées dans Kraif & Chen (2004).
Sur la base de ce mélange d'indices (distribution + positions + ressemblance), l'extraction des correspondances lexicales est effectuée couple de phrases par couple de phrases, en utilisant l'algorithme de meilleure affectation biunivoque (ou competitive linking algorithm, cf. Melamed 1997).
0 - on calcule d'abord les scores de tous les appariements possibles
1 - on enregistre l'appariement (u,u') qui obtient le meilleur score
2 - on supprime tous les appariements concurrents (impliquant u ou u')
3 - on retourne en 1 jusqu'à ce qu'il ne reste plus d'appariement candidat
En construction.
En construction.
En construction.
En construction.
Alinea propose deux principales options pour lancer l'alignement de deux fichiers :

Source : nom du fichier source.
Cible : nom du fichier cible.
Paramètres : nom du fichier de paramètres.
Paramètres phase 1 : possibilité de modifier les paramètres relatifs à la phase I (extraction de points d'ancrage).
Paramètres phase 2 : possibilité de modifier les paramètres relatifs à la phase II (calcul de l'alignement complet).
Balise de segmentation XML : indique le cas échéant le type d'élément XML marquant la segmentation en phrases.
Balise de tokenisation XML : indique le cas échéant le type d'élément XML marquant la segmentation en tokens.
Balises de préalignement : indique le cas échéant le type d'élément XML marquant un préalignement des fichiers (par exemple, si les fichiers sont alignés au niveau des chunk, des par, etc.). Plusieurs éléments peuvent être indiqués (séparés d'un espace). Des balises de préalignements peuvent même figurer dans des fichiers au format texte brut. Par exemple, pour un fichier ne comportant pas de codage XML, l'insertion d'une marque de préalignement <p/> permet de définir manuellement des points d'ancrage dans les fichiers source et cible (à condition d'indiquer l'élément p)..
L'alignement étant parfois assez long à calculer, il peut être intéressant de lancer une série d'alignements à la suite, de façon totalement automatique (par exemple de nuit).
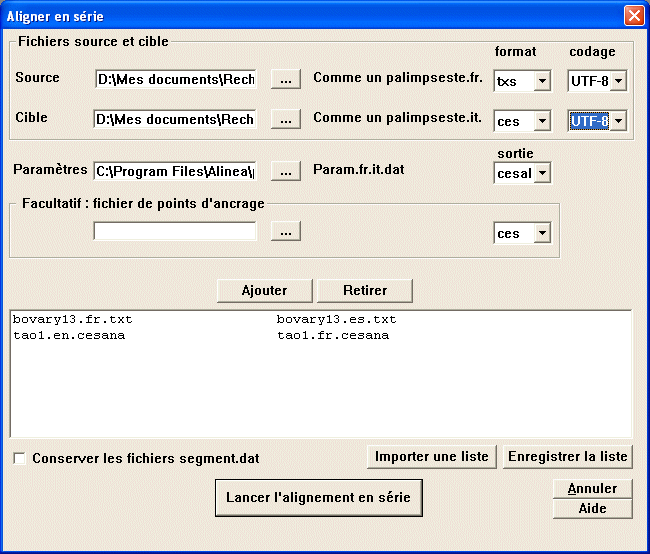
On trouve les mêmes entrées que précédemment, sauf qu'il est possible d'ajouter chaque couple de textes (avec ses paramètres) à une liste, qu'on peut éventuellement sauvegarder (dans l'éventualité d'un nouveau calcul avec de meilleurs paramètres).
Fichier de points d'ancrage : pour chaque couple de textes à aligner, on peut éventuellement indiquer un fichier de points d'ancrage permettant de guider l'alignement.
Conserver les fichiers segment.dat : la lecture de fichier au format texte ou xml, avant même de lancer la tâche d'alignement, peut s'avérer assez longue. Il est possible d'enregistrer le résultat de cette lecture, afin d'économiser du temps pour de futurs traitements : les fichiers segment.dat et token.dat sont des fichiers compilés, souvent volumineux, directement lisibles par Alinea, et qu'on peut conserver si l'on coche cette case.
La création d'un projet permet d'enregistrer toutes les phases intermédiaires de l'alignement, et de relancer le traitement à n'importe laquelle de ces étapes, avec un contrôle manuel plus fin sur les résultats (notamment en agissant sur les points d'ancrage).
En outre, l'extraction des correspondances lexicales n'est pour le moment disponible qu'à travers la création d'un projet.
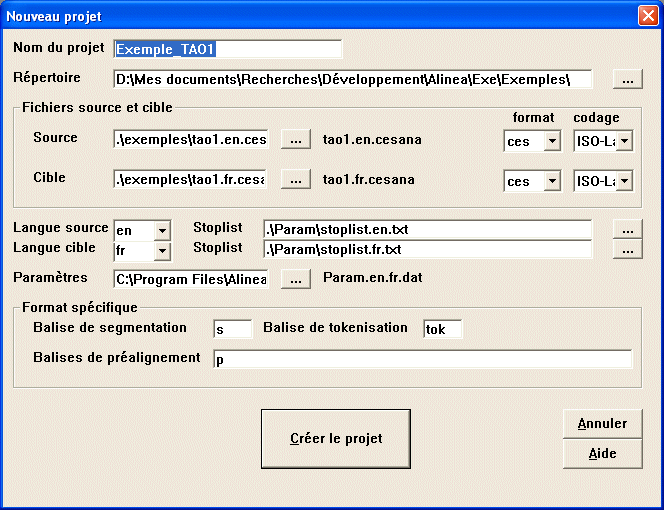
En plus du dialogue précédent, on y trouve des informations relatives au projet :
Nom du projet : quand on crée un projet, tous les fichiers intermédiaires sont enregistrés, afin de pouvoir être réexploités à une phase ultérieure. Le nom du projet indique comment tous les fichiers du même projet seront prefixés. Par exemple, pour un projet de préfixe test, on obtiendra les fichiers suivants:
test_Projet.prj
test_Ancrage.dat
test_AncrageTrans.dat
test_Corresp.dat
test_Parametres.dat
test_PoidsCognats.dat
test_Segment.en.dat
test_Segment.fr.dat
test_Stats.dat
test_Token.en.dat
test_Token.fr.dat
test_Transfuge.dat
Il est donc conseillé de donner un préfixe différent à chaque projet. Attention : ces fichiers peuvent devenir très volumineux pour de gros corpus. Il sont nécessaires tant que vous avez besoin d'éditer (ou de recalculer) l'alignement. N'hésitez pas à les détruire quand vous avez terminé vos traitements et obtenu l'alignement qui vous convient.
Répertoire : Répertoire où seront enregistrés tous les fichiers intermédiaires du projet.
Langue source / cible : Suffixes utilisés pour différencier les fichiers des deux langues. En général, il convient de choisir le code langue abrégé (en, fr, it, es, pt, de, etc.) précédé d'un point. La concaténation des deux suffixes donne l'extension du fichier de paramètre par défaut (s'il existe). Par exemple param.en.fr.dat pour les suffixes .en et .fr.
La création ou l'ouverture d'un projet existant (ainsi que le menu Projet en cours) donne accès au dialogue Projet, qui est en quelque sorte le tableau de bord duquel on peut accéder aux différentes étapes du projet.
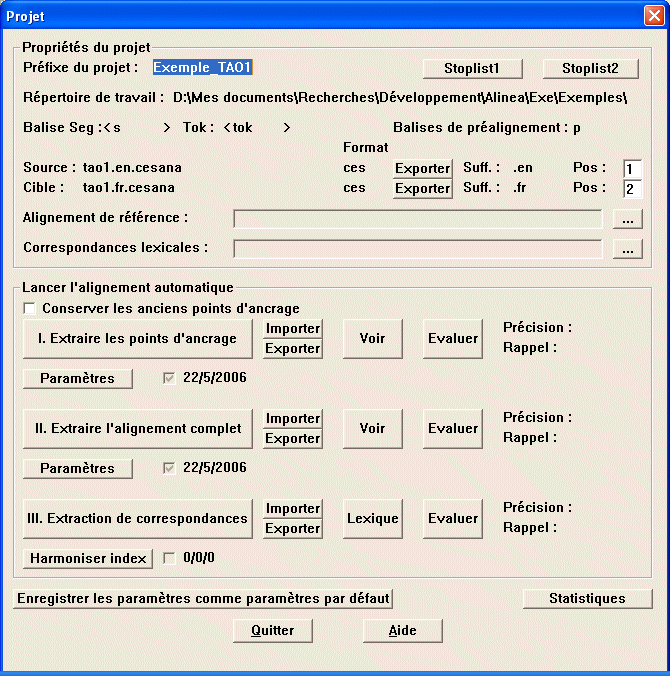
Le haut du dialogue récapitule les informations du projet courant.
Les deux boutons Exporter en face des noms de fichier source et cible permettent d'obtenir les fichiers segmentés au niveau des phrases au format CESAna.
Les deux champs Pos permettent d'indiquer les positions respectives des ids source et cible lors de l'importation d'un alignement à partir d'un fichier extérieur. Par exemple, si on a un fichier quadrilingue :
<link xtargets="s14 s15 ; s22 s23 ; s19 ; s7 s8">
<link xtargets="s16 s17 s18 s19 s20 ; s24 s25 s26 ; s20 s21 s22 ; s9
s10 s11">
<link xtargets="s21 s22 ; s27 ; s23 s24 ; s12">
si l'espagnol est en position 4 et le français est en position 2, alors Pos source = 4 et Pos cible = 2 permet d'extraire l'alignement suivant, correspondant au couple es-fr :
<link xtargets="s7 s8 ; s22 s23">
<link xtargets="s9 s10 s11 ; s24 s25 s26">
<link xtargets=" s12 ; s27">
Alignement de référence : Permet d'importer un alignement des deux textes qui servira à évaluer (en terme de précision et rappel) les alignements obtenus automatiquement par Alinea. Cette option est utile pour la mise au point d'un jeu de paramètres adapté à un corpus donné : on constitue d'abord un alignement de référence exempts d'erreur, manuellement (grâce à l'éditeur), sur un échantillon représentatif du corpus que l'on veut traiter. Puis on relance l'alignement automatiquement sur cet échantillon et l'on essaie j'ajuster les paramètres afin d'obtenir les meilleurs résultats possibles. Les paramètres importants sont en général : le rapport des longueurs, la taille de l'espace de recherche (largeur de la bande autour de la diagonale), les probabilités de transition, et l'étape de préalignement à laquelle on désire s'arrêter. Ces aspects seront développés ultérieurement dans une version plus complète de l'aide.
Correspondances lexicales : Permet d'importer des correspondances lexicales de référence, qui serviront à évaluer (en terme de précision et rappel) les correspondances obtenus par Alinea (non disponible).
Les phases I, II et III correspondent respectivement à l'extraction de points d'ancrage, l'extraction de l'alignement complet et l'extraction de correspondances lexicales. Les phases doivent être effectuées l'une après l'autre, chacune utilisant les résultats de la précédente. Par exemple, la phase II ne peut être lancée si la I n'a pas déjà été exécutée (sauf si un fichier de point d'ancrages à été importé). Pour chacune des phases on trouve les options suivantes :
Extraire : Lance l'éxécution de la phase correspondante. La case à cocher placée sous le bouton indique si une extraction a été déjà lancée, ainsi que la date de la dernière extraction.
Paramètres : Donne l'accès aux paramètres liés à chaque extraction.
Importer / Exporter : Permet d'importer l'alignement (ou les correspondances lexicales) à partir d'un fichier externe (format CESAlign) ou d'exporter l'alignement courant vers un fichier externe (CESAlign, texte ou HTML).
Voir : Permet de visualiser et d'éditer l'alignement courant à travers le dialogue Navigateur bi-textuel .
Evaluer : Si un alignement de référence a été préalablement chargé, permet d'évaluer par comparaison la qualité de l'alignement courant (calcul de précision et rappel).
Conserver les anciens points d'ancrage : L'extraction des points d'ancrage est une opération itérative, de nouveaux points étant ajoutés entre les points déjà trouvés. Ainsi, il est possible de relancer l'extraction de points d'ancrage sur la base des points d'ancrage existants (qui ont pu faire l'objet d'un intervention manuelle).
Harmoniser index : Quand on lance l'extraction des correspondances lexicales, il faut harmoniser les fichiers du projet avec les index des fichiers de paramètres contenant des données sur les occurrences et coocurrences bilingues des lexèmes. Cette opération est en principe lancée automatiquement, mais il se peut que suite à une modification des fichiers de paramètres, les index du projet ne soient plus en cohérence (ce qui pourrait aboutir à de très mauvais résultats). En cliquant sur ce bouton, on est sûr que les index seront à nouveau harmonisés (cette opération peut prendre du temps pour de gros textes).
Enregistrer les paramètres comme paramètres par défaut : Si on estime que les paramètres tels qu'on les a affinés pour le projet courant sont optimaux, et généralisables, on peut les enregistrer comme paramètres par défaut pour le couple de langues. Tous les nouveaux projets basés sur ce couple de langues utiliseront, par défaut, ces nouveaux paramètres.
Statistiques : Indique les statistiques relatives aux fichiers source et cible et aux alignements extraits.
En construction.
En construction.
En construction.
Lorsqu'on clique sur un des boutons Voir, on peut accéder à la suite de points d'ancrage ou à l'alignement qui a été extrait. Cette fenêtre permet à la fois de visualiser les résultats, d'effectuer des recherche dans le bi-texte, et de modifier les alignements extraits.
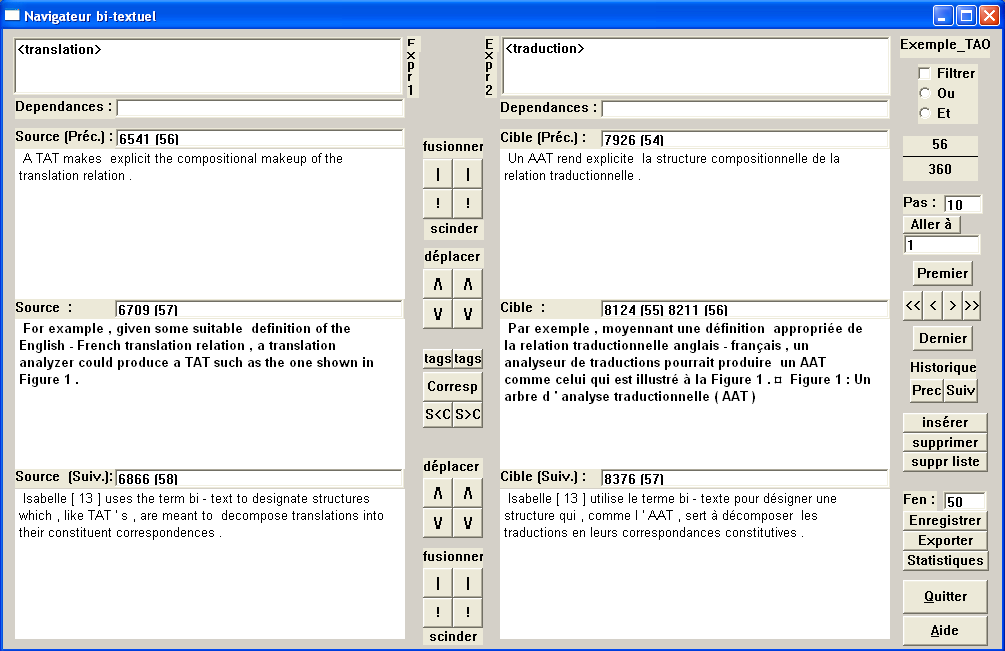
Cette fenêtre présente simultanément, à gauche pour la langue source et à droite pour la langue cible, trois groupes de phrases alignés. Chacun de ces groupes peut correspondre à un nombre indéfini de phrases consécutives. Dans le cas d'un alignement automatiquement extrait par Alinéa, un groupe peut intégrer au maximum 3 phrases.
Le couple courant, affiché en gras, et dont le numéro est indiqué en haut à droite, est représenté par les deux zones de texte centrales. Le textes de ces zones peut faire l'objet de copier/coller et d'édition, mais le texte original est raffraîchi à chaque déplacement. Alinea permet d'éditer l'alignement, mais pas les textes sous-jacents. Le symbole ¤ représente le caractère de concaténation entre les phrases d'un même groupe.

Des boutons de navigation situés à droite permettent la navigation dans le fichier d'alignement. Les boutons << / >> autorisent le recul / avance rapide de 10 en 10 (par défaut).
Au dessus des boutons de navigation se situent des champs indiquant le numéro de couple actuel (ici 56 sur 360), un champ Pas définissant le nombre de couples sautés lors du recul << / avance >> rapide, ainsi qu'un bouton Aller à permettant d'atteindre directement un couple en tapant son numéro dans le champ situé juste au dessous.
Noter que lorsqu'aucun bouton n'a le focus (p.ex. en cliquant sur le fond gris), les flèches du clavier permettent également de se déplacer, tout comme les touches début et fin.

Il est également possible d'utiliser l'historique pour revenir (en arrière puis en avant) vers les derniers couples parcourus, grâce aux boutons ci-dessus.

Les blocs de boutons situés entre chaque demi-fenêtre permet d'effectuer des opérations d'édition. Les boutons qui suivent sont doubles, et n'ont d'effet que sur la moitié correspondante du bi-texte.
\/ : Déplacement de la dernière phrase du groupe courant vers le début du groupe suivant.
/\ : Déplacement de la première phrase du groupe suivant vers la fin du groupe courant.
| : Fusion du groupe courant avec le groupe suivant. Attention : une telle opération implique un décalage en cascade vers le haut de tous les groupes qui suivent.
! : Scission de la dernière phrase du groupe courant vers un nouveau groupe suivant. Attention : une telle opération implique un décalage en cascade vers le bas de tous les groupes qui suivent.
Sur la partie droite, on a accès à d'autres boutons pour l'édition, pour agir en parallèle des deux côtés du bi-texte :
insérer : Insertion de nouveaux couples de phrases, situés entre le couple courant et le couple suivant. En cliquant sur ce bouton, on accède à un dialogue donnant, pour chaque côté, la liste des phrases insérables. Il faut prendre soin de sélectionner un nombre identique de phrases de chaque côté afin de former les nouveaux couples.
supprimer : Suppression du couple courant.
suppr liste : Suppression de la liste des couples sélectionnés. En cliquant sur ce bouton, on accède à un dialogue donnant la liste des couples supprimables.

Il est possible de rechercher des expressions tant dans le texte source que dans le texte cible, au moyen des champs situés en haut du dialogue. La case à cocher Filtrer permet d'activer ou de désactiver le filtrage des expressions : s'il est activé, les boutons de navigation < et > auront pour effet de rechercher les occurrences précédente et suivante des expressions recherchées (ici les unités translation et traduction). Le bouton radio Ou/Et indique le mode de combinaison logique des critères dans la source et la cible.
Dans ce formalisme, un token est représenté par deux chevrons <>, à l'intérieur desquels on énumère les critères de recherche, sous la forme d'une liste attribut=valeur (sans espacement autour du signe =). Les attributs font références aux étiquettes morphosyntaxiques liées à chaque token. Par exemple, en txs, comme en CesAna, on a les attributs suivant :
- orth : Forme orthographique (p. ex. "aidais")
- base : Lemme (forme canonique, p. ex. "aider")
- ctag : Catégorie (ou partie du discours, p. ex. "Verb")
- msd : Description en traits morphosyntaxiques (p. ex. "P1 Sg Ind Imp")
Dans le cas de textes ne comportant pas d'étiquettes, chaque token se voit affecté l'attribut par défaut : orth
Exemple :
<>
désigne un token quelconque
<orth=aide> ou <aide>
désigne "toute occurrence de la forme aide" (orth est l'attribut par défaut)
<base=aider,ctag=Verb>
désigne "toute occurrence du verbe aider, quelle que soit sa forme"
<ctag=verb,msd=P1 Sg Imp>
désigne "toute occurrence d'un verbe conjugué à la première personne du singulier de l'imparfait
La comparaison des valeurs d'attributs n'est pas sensible à la casse, sauf pour orth et base : <base=aider,ctag=Verb> est équivalent à <base=aider,ctag=verb>
Notons que les codes de traits et de catégories dépendent du tagset (jeu d'étiquette) lié à l'étiquetage (p. ex. certains jeux peuvent imposer Ver, ou V au lieu de verb).
Les valeurs des attributs, en tant que chaînes de caractères, peuvent faire l'objet d'expressions régulières : il faut alors préfixer l'expression par un slash /. Par exemple :
</expliqu.*>
permet de rechercher des occurrences telles que "expliquait", "expliquer", etc.
Les opérateurs d'expression régulière peuvent s'appliquer sur les tokens. Voici les opérateurs de répétition :
* : 0...n occurrences
+ : 1...n occurrences
? : 0...1 occurrence
{n} : de 0 à n occurrences
{n,m} : de n à m occurrences
Le point . désigne un caractère quelconque. L'antislash \ permet d'échapper aux caractères réservés. Les crochets permettent de définir une alternative de caractères [aA] ('a' ou 'A') ou un intervalle [0-9].
</[sS]\.?[nN]\.?[cC]\.?[fF]\.?>
permettra de rechercher des occurrences telles que "sncf", "s.n.c.f", "SNCF", etc.
La disjonction (le OU logique), notée | , combinée aux parenthèses, permet d'énumérer des possibilités alternatives.
Par exemple :
</expli(qu|c).*>
désigne des occurrences telles que "expliquait", "explication", etc.
<ctag=/(verb|adj),msd=/ppass>
désigne des occurrences de formes au participe passé identifiées comme verbes ou adjectifs.
^ : désigne le début d'une chaîne
$ : désigne la fin d'une chaîne
<base=/er$,ctag=verb>
désigne un verbe se terminant par "er"
^<ctag=conj>
désigne une conjonction située en début de phrase
Il est possible d'exprimer la négation d'un critère, grâce à l'opérateur !, placé devant le signe =.
Par exemple :
<base=/ment$,ctag!=adv>
désigne les mots se terminant par -ment et n'étant pas des adverbes.
Une requête peut également porter sur une suite de tokens :
<base=mettre><en><oeuvre>
permet de rechercher des occurrences telles que "mettra en oeuvre" "mise en oeuvre", etc.
Les opérateurs de répétition sont les mêmes que précédemment : * + ? {}.
Par exemple :
<base=mettre><>?<en><oeuvre>
permet de rechercher des occurrences telles que "mettra demain en oeuvre" "mise en oeuvre", etc.
<base=mettre><>*<en><oeuvre>
permet de rechercher des occurrences telles que "mettra dès maintenant en oeuvre" "mise en oeuvre", etc.
<base=mettre><>+<en><oeuvre>
permet de rechercher des occurrences telles que "mettra sur le champ en oeuvre", mais pas "mise en oeuvre".
<base=mettre><>*<en>(<oeuvre>|<route>|<action>)
permet de rechercher des occurrences telles que "mettra en route" "mis en action", etc.
Les expressions parenthésées peuvent être combinées à un niveau de profondeur quelconque. Il est également possible d'indiquer un intervalle pour la répétition d'une expression, grâce aux crochets :
(<do>|<ré>|<mi>){2,4}
permet de rechercher des suites telles que "do do", "mi ré do" et "ré do ré mi"
Dans le cas de fichiers comportant une analyse des dépendances, tels que les sorties du parseur robuste XIP de Xerox, il est possible d'ajouter des contraintes de recherche concernant ces dépendances. Il convient au préalable d'attribuer des identificateurs ($1, $2, $3, etc.) aux tokens concernés par la relation, puis d'indiquer les relations dans le champ Dépendances. Les relations doivent être exprimées entre parenthèses, avec l'opérateur suivi des arguments séparés par des virgules. Plusieurs relations peuvent être indiquées, séparées par des espaces.
Expr : <base=recherche,$1><>*<ctag=verb,$2>
Dépendances : (SUBJ,$1,$2)
permettra de rechercher des occurrences telles que "les recherches sur la conservation se concentrent maintenant sur " ou "La recherche offre donc de nouvelles perspectives", etc.
Un click sur Enregistrer permet de sauvegarder les dernières modifications (attention : aucun retour en arrière n'est possible).
L'exportation vers une sortie texte, html ou CESAlign tient compte du filtrage éventuellement posé par l'utilisateur. Si ce filtrage est actif, seuls les couples filtrés seront exportés. Le champ Fen permet de définir la largeur, en caractères, des contextes gauche et droit pour l'exportation en format KWIC.
Il est également possible d'afficher les statistiques relatives aux textes extraits (nombre de tokens, de segments, etc.) ainsi qu'aux résultats du dernier alignement automatique (les modifications manuelles sont sans incidence sur les statistiques).
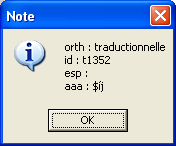
Quand un token est sélectionné dans la fenêtre centrale, un click sur le bouton tags correspondant permet d'afficher un dialogue indiquant les différentes étiquettes associées à ce token : id, orth, base, ctag, msd, etc. (ces étiquettes dépendent des fichiers sources). Par exemple, pour un texte brut (sans étiquetage) on obtient les informations suivantes (le mot traductionnelle ayant été sélectionné). L'attribut aaa est une entrée d'index utilisée dans le fichier de paramètres pour les correspondances lexicales.
7.1 J'ai peu de temps. Dois-je maîtriser les finesses du logiciel et ses paramétrages complexes pour utiliser Alinea ?
7.2 Les résultats de l'alignement sont mauvais. Que dois-je faire pour les améliorer ?
7.3 Est-il important de suivre une nomenclature pour les fichiers ?
7.4 Peut-on intégrer plusieurs fichiers source et cible dans un même projet?
7.5 Peut-on modifier les fichiers source et cible à travers la fenêtre du navigateur ?
7.6 Peut-on modifier la segmentation des fichiers source et cible à travers la fenêtre du navigateur ?
7.7 Lorsque je lance Alinea, j'obtiens l'erreur suivante
7.8 Alinea se bloque pendant une opération d'alignement
Non. L'option Aligner directement du menu Aligner permet de lancer l'alignement en n'indiquant que les noms des fichiers source et cible (à la condition qu'ils soient dans des formats reconnus). Si aucun paramètre n'existe pour le couple de langues, Alinea utilisera des paramètres par défaut. Si les textes sont bien parallèles, on a toute chance d'obtenir des résultats suffisants. Il est ensuite possible d'exporter l'alignement dans le format désiré.
Pour contrôler l'exécution correcte de chaque étape, il faut créer un projet. On peut alors, en examinant les statistiques, comparer le nombre de segments source et cible.
Si le rapport entre ces nombres est très déséquilibré (par exemple avec 2 fois plus de segments source), il faut en identifier la cause :
# séparation des paragraphes (choisir \n ou \n\n)
separePara=\n\n
En règle générale, il faut vérifier la correction des points d'ancrage à l'issue de la phase I, et au besoin en rajouter manuellement si l'espace entre deux points est trop important (p.ex. supérieur à 50 phrases). Après enrichissement et correction manuelle, on peut éventuellement relancer l'extraction de points d'ancrage en conservant les anciens : lorsque les points d'ancrage ont été enrichis et corrigés manuellement, de nouveaux points corrects peuvent parfois être rajoutés automatiquement.
Si les résultats sont toujours mauvais, il faut intervenir sur les paramètres de la phase II. Par exemple, il se peut que les 8 transitions de bases ne soient pas suffisantes (p.ex. pour prendre en compte des alignement 1:4 ou 1:5). Dans ce cas on peut essayer de décocher Transitions fixes, avec un Rapport des longueur maximum égal à 2.
Oui, les conventions de nommage d'Alinea permettent de simplifier un certain nombre de manipulation :
Ces conventions sont simples. Les fichiers sources et cibles sont nommés suivant le modèle suivant :
NOM.L1.FFF et NOM.L2.FFF
Le fichier d'alignement correspondant sera alors nommé suivant le modèle :
NOM.L1-L2.FFF
Oui. Il est possible, lors de la création d'un projet ou de l'alignement direct, d'utiliser des caractères jokers (astérisque * ou point d'interrogation ?), afin d'identifier plusieurs fichiers d'un coup. Par exemple, si l'on a des textes de la forme :
verne_80jours.fr.txt
verne_5semaines.fr.txt
verne_lune.fr.txt
verne_80jours.en.txt
verne_5semaines.en.txt
verne_lune.en.txt
Alors on peut construire un projet en définissant les fichiers source et cible comme :
verne*.fr.txt et verne*.en.txt
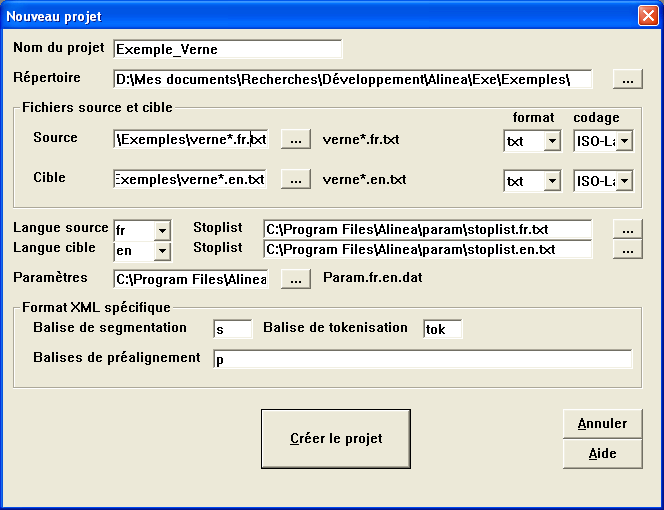
Les fichiers ainsi groupés doivent tous appartenir au même dossier (pour chaque langue). Ne seront pris en compte que les couples de fichiers source et cible respectant les conventions de nommage précédemment décrites.
Pour le moment non : dans le codage interne des textes, chaque token se voit attribué une série d'étiquettes. Le texte simple affiché dans la fenêtre du navigateur ne donne accès qu'à une partie de ces informations, qui ne sont donc pas directement modifiables.
L'édition de l'alignement permet de grouper des phrases ou de scinder des groupes de phrases. Peut-on scinder une phrase (qui correspondrait en fait à plusieurs phrases non identifiées lors de la segmentation) ? Pour le moment non, mais cette option sera disponible dans une prochaine version.
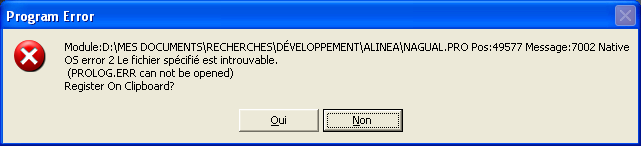
Il s'agit sans-doute d'un problème d'installation : au lieu de créer un raccourci vers Alinea.exe, vous avez peut-être copié Alinea.exe en dehors de son répertoire d'origine (p.ex. sur le bureau).
L'alignement est une opération coûteuse en calcul. Sur de très gros textes, les calculs peuvent prendre plusieurs dizaines de minutes, voire même quelques heures (tout dépend bien sûr de la mémoire vive et du processeur). Il est conseillé d'utiliser Alinea avec une mémoire vive d'au moins 256 Mo.
La phase de préalignement, pour un très gros projet, peut se révéler assez longue car le temps de calcul augmente de manière non linéaire, en fonction de n log(n) où n représente le nombre de phrases des textes. Cette étape peut donc prendre beaucoup de temps sans être plantée : patience ! Par exemple, pour un projet de 34 905 x 28 547 segments dans chaque langue (671 769 x 705 565 tokens), l'extraction des points d'ancrage a pris 54 minutes sur un Pentium 4 à 2,2 GHz avec 512 Mo de RAM.
Pour la phrase II, la taille des textes est moins problématique : la longueur de la phase d'extraction de l'alignement est linéaire en fonction de la taille des corpus (à condition de ne pas saturer la mémoire).
Cependant, lorsque la charge est trop lourde en mémoire, Alinea est susceptible de se planter : c'est généralement dû à un alignement lancé entre des points d'ancrage trop espacés (plus de 500 phrases), ou pour des phrases trop longues (il est déconseillé de travailler sur des segments de plus de 200 tokens).
Bellman, R. (1957) Dynamic programming, Princeton , Princeton University Press.
Brown, P., Lai, J., Mercer, R. (1991) Aligning Sentences in Parallel Corpora. In Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics, ACL-91, Morristown , NJ , pp. 169-176.
Davis, M. W., Dunning T. E., Ogden W. C. (1995) Text Alignment in the Real World : Improving Alignments of Noisy Translations Using Common Lexical Features. In Proceedings of EACL 95, 8 p. (disp. à l’adresse : http://www.crl.nmsu.edu).
Gale, W., Church, K. W. (1993) A Program for Aligning Sentences in Bilingual Corpora. Computational Linguistics, vol. 19, n. 1, pp. 75-91.
Kraif, O. (1999) Identification des cognats et alignement bi-textuel : une étude empirique, Actes de la 6ème conférence annuelle sur le Traitement Automatique des Langues Naturelles, TALN 99, Cargèse, 12-17 juillet 1999, pp.205-214
Kraif, O. (2001) Constitution et exploitation de bi-textes pour l’Aide à la traduction, Thèse de doctorat, sous la dir. de Henri Zinglé, Université de Nice Sophia Antipolis.
Kraif O., B. Chen (2004) Combining clues for lexical level aligning using the Null hypothesis approach, in Proceedings of Coling 2004, Geneva, August 2004 , pp. 1261-1264.
Lopes G., J. Mexia (2001). Cognates alignment. In Proceedings of MT Summit VIII .
Melamed I. D. (1997) A Word-to-Word Model of Translational Equivalence, 35th Conference of the Association for Computational Linguistics (ACL'97), Madrid.
Simard, M. (2000) Multilingual text alignment – Aligning three or more versions of a text. In Véronis, J. (Ed.), Parallel Text Processing, Dordrecht , Netherlands , Kluwer Academic Publishers, § 3, 20 p.
Simard, M., Foster, G., Isabelle, P. (1992) Using Cognates to Align Sentences in Bilingual Corpora. Fourth International Conference on Theoretical and Methodological Issues in Machine Translation of Natural Languages, TMI-92, Montréal, CCRIT, pp. 67-81.